今年国庆长假没有出游计划,不过可以在朋友圈周游世界。周游世界的同时正好有点时间来博客除除草了,2017年已过四分之三,目前只留下一篇博客(囧)。今天无意间翻到3年前回复过的一个帖子:用SAS做成语接龙。编程思路如下:首先导入成语大全,提取首尾汉字,将所有成语放入哈希表中,然后将成语最后一个汉字去哈希表中查询匹配,如果成功匹配则把哈希表中匹配的成语最后一个汉字做为KEY去查询匹配,直到遍历整个哈希表。更新的代码(SAS 9.2 for Windows)如下:
/*导入成语列表*/
proc import datafile="D:\Demo\成语大全.txt"
out=idiom_list
replace;
getnames=no;
guessingrows=32767;
run;
/*提取首尾汉字*/
data idiom_list;
set idiom_list(rename=VAR1=IDIOM);
length FIRST_C END_C $2.;
FIRST_C=prxchange('s/^(.{2}).+/\1/', 1, cats(IDIOM));
END_C=prxchange('s/.+(.{2})$/\1/', 1, cats(IDIOM));
run;
/*初始成语*/
%let start_idiom=胸有成竹;
/*查询*/
data _null_;
if _n_=1 then do;
if 0 then set idiom_list;
dcl hash h(multidata: 'Y');
h.definekey('FIRST_C');
h.definedata('IDIOM', 'FIRST_C', 'END_C');
h.definedone();
end;;
do until(last);
set idiom_list idiom_list end=last;
h.add();
end;
set idiom_list(where=(IDIOM="&start_idiom") rename=END_C=FIRST_C keep=IDIOM END_C);
put IDIOM=;
if h.find(key: FIRST_C)=0 then put IDIOM=;
do i=1 to 100;
if h.find(key: END_C)=0 then put IDIOM=;
if h.find(key: END_C)=0 then do;
rc=h.find_next(key: END_C);
put IDIOM=;
end;
end;
run;
结果如下:胸有成竹、竹苞松茂、茂林修竹、竹报平安、安安稳稳、稳操胜券。
上面的帖子其实有点像深度优先搜索(Depth-First-Search,简称DFS)。除了哈希表的方法,还可以用双SET加KEY选项来解决。比如这个帖子。数据集如下图:
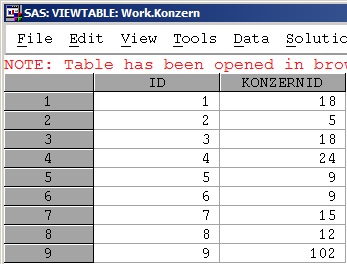
楼主的问题是找最高级,如上图中ID为2的下一级是5,5的下一级是9,9的下一级是102,102没有下一级了,那么2的最高级就是102。编程思路和上面HASH方法类似,即用当前的KONZERNID作为索引ID去查找匹配,直到匹配不成功。更新的代码如下:
data konzern;
input ID KONZERNID;
cards;
1 18
2 5
3 18
4 24
5 9
6 9
7 15
8 12
9 102
;
run;
/*Create index*/
data konzern(index=(ID));
set konzern;
run;
/*Lookup*/
data highestid;
set konzern;
ID_INIT=ID;
KONZERNID_INIT=KONZERNID;
HIGHESTID=ID;
do i=1 to 100;
ID=KONZERNID;
HIGHESTID=ID;
set konzern key=ID/unique;
if _IORC_^=0 then leave;
end;
keep ID_INIT KONZERNID_INIT HIGHESTID;
run;
结果如下:
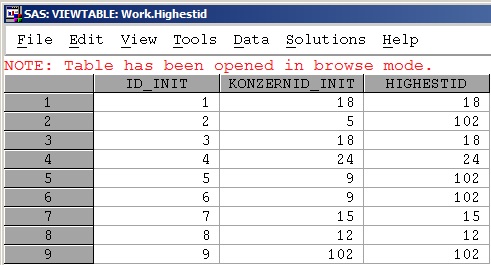
以两种方法各有利弊,因为哈希表是存储在内存中,所以当数据较大时可能会导致内存不足。而第二种方法因为有多次SET操作,数据较大时效率会大大降低。故在实际应用中应该根据具体情况而定